Die unsichtbare Ebene flüssigen Sprechens: den japanischen Tonhöhenakzent verstehen
Wenn Japanisch natürlich klingt, liegt das nicht nur an korrekter Grammatik oder passender
Wortwahl.
Jedes Wort trägt eine charakteristische phonologische Kontur: einen Anstieg, einen Akzentkern oder eine gehaltene
hohe Tonlage, die Muttersprachler sofort hören, obwohl Sprachlerner fast nie darauf aufmerksam gemacht werden.
Dieser Leitfaden
macht diese verborgenen Konturen sichtbar und greifbar. Er beginnt mit grundlegenden Begriffen, behandelt die
vier zentralen Tonhöhenmuster und endet damit, wie sie in echten Sätzen vorkommen.
Grundlage: Moren und Tonhöhe
Bevor wir uns die vier verschiedenen Tonhöhenmuster ansehen, müssen wir klären, wie Laute im Japanischen zeitlich gemessen werden. Wenn du aus dem Deutschen kommst, bist du eine Druckakzentsprache gewohnt, die auf Silben basiert. Druckakzent bedeutet, dass du beim Aussprechen eines Wortes bestimmte Silben hervorhebst, indem du sie lauter, länger und in höherer Tonlage sprichst. Japanisch dagegen ist eine Tonhöhenakzentsprache, die auf gleichmäßigen rhythmischen Takteinheiten basiert, den sogenannten Moren (拍).
Moren vs. Silben
Eine Mora ist die grundlegende Zeiteinheit von Laut und Rhythmus im Japanischen. Um den Unterschied zu verstehen, sehen wir uns das Wort 東京. an. Ein deutscher Muttersprachler würde dieses Wort wahrscheinlich in zwei Silben einteilen: とう und きょう. Ein japanischer Sprecher nimmt es allerdings als genau vier gleichmäßig verteilte Taktschläge wahr: と-う-きょ-う.
Beim Zählen von Moren solltest du dir zwei wichtige Regeln merken:
- Kleine Kombinationszeichen (wie きょ, しゃ, じょ) zählen nur als eine Mora, nicht als zwei.
- ん, っ und das Langtonzeichen 'ー' zählen jeweils ebenfalls als eine einzelne Mora.
Wenn ein japanisches Wort betont ist, besitzt es einen deutlich hörbaren musikalischen Akzentkern zwischen genau zwei aufeinanderfolgenden Moren. Genauer gesagt hat ein betontes Wort genau einen Akzentkern (アクセント核). Bekannte Wörterbücher wie 大辞泉 oder 大辞林 verwenden Zahlen, um die genaue Position dieses Akzentkerns im Wort anzugeben:
- [0] bedeutet, dass es keinen Akzentkern gibt; das Wort ist also flach und fällt nicht ab.
- [1] bedeutet, dass die erste Mora betont ist.
- [2] bedeutet, dass die zweite Mora betont ist, und so weiter.
akusento vereinfacht diese Notation, indem betonte Moren im Text direkt mit diesem roten Symbol für den Akzentkern markiert werden: ア. So musst du Moren nicht manuell zählen und siehst sofort, wo der Akzent zu setzen ist.
Die Tonhöhe sichtbar machen
Um klar zu sehen, wie ein Akzentkern in der Praxis funktioniert, können wir uns das Ergebnis einer echten Tonhöhenanalyse ansehen. Unten siehst du eine Grundfrequenzkurve (F0) aus der Sprachanalyse-Software Praat. Sie zeichnet die musikalische Tonhöhe der Stimme eines Muttersprachlers in Hertz (Hz) über die Zeit auf, während sie sich über die einzelnen Taktschläge (Moren) bewegt.
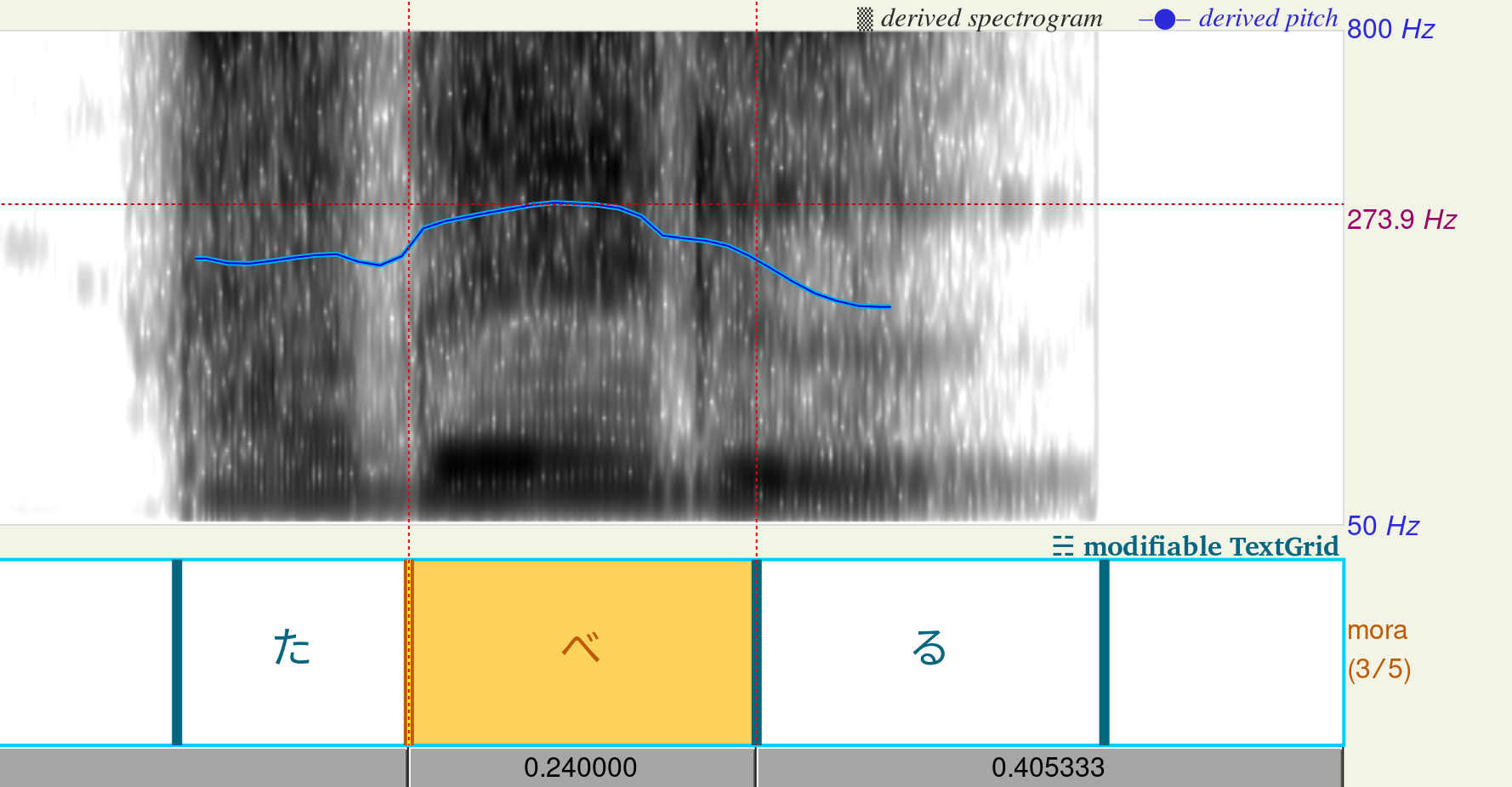
Wenn man diese Hz-Kurve nach Moren aufschlüsselt, wird die Mechanik des Akzentkerns deutlich sichtbar:
- Die hohe Mora (Hz-Spitze): Die betonte Mora ist der letzte Schlag, der auf einer hohen musikalischen Frequenz gehalten wird (einem höheren Hz-Wert).
- Der Akzentkern (der Akzentkern): Das ist die genaue Grenze direkt nach dieser hohen Mora. Sie wirkt wie eine Klippe.
- Die niedrigen Moren (nach dem Akzentkern): Unmittelbar nach dem Überschreiten dieser Grenze schwingen deine Stimmbänder langsamer. Die Tonhöhe stürzt auf eine niedrigere Frequenz ab (einem niedrigeren Hz-Wert) schon auf der nächsten Mora und bleibt bis zum Ende des Wortes niedrig.
Die vier zentralen Tonhöhenmuster
Im Standard-Tokyo-Japanisch (標準語) lassen sich alle Wörter in die folgenden vier Tonhöhenakzentmuster einteilen:
平板 (flaches Muster)
Beginnt auf der ersten Mora tief, steigt auf der zweiten an und bleibt hoch. Die Tonhöhe fällt nicht ab wenn eine Partikel (wie に) angehängt wird.
頭高 (kopfhohes Muster)
Beginnt auf der ersten Mora hoch, fällt dann sofort auf der zweiten Mora ab und bleibt niedrig. Partikel bleiben niedrig.
中高 (mittelhohes Muster)
Beginnt tief, steigt an und fällt dann irgendwo in der Mitte des Wortes ab. Partikel bleiben niedrig.
尾高 (endhohes Muster)
Beginnt tief, steigt an und bleibt bis zur letzten Mora des Wortes hoch. Die Tonhöhe fällt unmittelbar nach dem Wort ab und führt dazu, dass Partikel in tieferer Tonhöhe angehängt werden.
Akzentphrasen: wie Wörter zusammenhängen
Bis hierhin haben wir den Tonhöhenakzent so betrachtet, als würde jedes Wort isoliert ausgesprochen. In der Praxis funktioniert Japanisch anders. Wörter verbinden sich mit Partikeln, Modifikatoren mit Nomen, Verben mit Hilfsverben, und mehrere geschriebene Wörter können als eine prosodische Einheit ausgesprochen werden. Diese Einheit nennt man Akzentphrase, kurz AP (アクセント句).
Was ist eine Akzentphrase?
Eine Akzentphrase ist ein kurzer Abschnitt gesprochener Sprache mit einer durchgehenden Tonhöhenkontur. Praktisch bedeutet das: Sie kann keinen oder einen Akzentkern aufweisen. Wenn ein weiterer starker Akzentkern auftreten würde, beginnt das Japanische stattdessen eine neue Akzentphrase.
Deshalb gehören Partikel oft zum Wort davor, während ein neues Inhaltswort in der Regel eine neue Phrase beginnt:
- 雨が ist eine Akzentphrase.
- 本を ist auch eine Akzentphrase.
-
本 を ・読 む besteht aus zwei Akzentphrasen, die jeweils einen einzelnen Akzentkern besitzen.
Wie akusento Akzentphrasen darstellt
In akusento zeigt die rote Markierung den Akzentkern, während der Mittelpunkt ・ eine Grenze zwischen Akzentphrasen markiert. Der Punkt ist kein Teil der japanischen Interpunktion und bedeutet auch nicht immer, dass man pausieren sollte. Er zeigt lediglich, dass die Tonhöhenkontur dort neu ansetzt.
Ein Satz kann zum Beispiel so angezeigt werden:
雨が・やんだら・出かけようと・思って・いたのに
Jeder Abschnitt zwischen den Punkten ist eine Akzentphrase. Manche Phrasen haben einen sichtbaren roten Akzentkern. Andere sind flach und haben überhaupt keinen sichtbaren Akzentkern.
Warum Akzentphrasen wichtig sind
Akzentphrasen sind wichtig, weil Tonhöhenakzent auf Satzebene nicht einfach eine Liste von Wortakzenten ist. Ein Wort kann seinen ursprünglichen Akzent verlieren, sich an Partikel anhängen, in einem Kompositum verbinden oder sich je nach Grammatik und Kontext von einem benachbarten Wort lösen.
Deshalb sind bloße Akzentzahlen im Wörterbuch nur ein Startpunkt. Ein Wörterbuch kann dir nur erklären, welchen Akzent ein Wort isoliert hat; es zeigt nicht, wie sich dieses Wort innerhalb eines vollständigen Satzes verhält. akusento nutzt Akzentphrasen, um den Satzryhtmus sichtbar zu machen, der entsteht, nachdem Partikel, Komposita, Konjugationen und Deakzentuierungsregeln angewendet wurden.
Die Markierung für Akzentphrasengrenzen ・ sollte als Hinweis auf die Tonhöhengruppierung gelesen werden, nicht als Satzzeichen. In natürlicher Sprache sind manche Grenzen fließend, während andere mit einer tatsächlichen Pause oder einem Komma zusammenfallen können. Akzentphrasengrenzen sind außerdem nicht immer vollständig eindeutig: Verschiedene Sprecher, Sprechgeschwindigkeiten, Betonungen und Analysekonventionen können denselben Satz leicht unterschiedlich gruppieren. akusento zeigt eine kontextbewusste Vorhersage einer natürlichen Lesart, nicht die einzige mögliche Aussprache.
Tonhöhenakzent von Verben: die Heiban/Kifuku-Abkürzung
Der Tonhöhenakzent von Verben wirkt zunächst kompliziert, weil scheinbar jede Konjugation ihre eigene Kontur hat. Aber für die meisten praktischen Zwecke sind Verben viel einfacher als Nomen. Du musst nicht vier verschiedene Tonhöhenmuster für jede Form auswendig lernen. Du musst hauptsächlich wissen, ob die Wörterbuchform zu einer von zwei binären Gruppen gehört: Heiban oder Kifuku.
Die zwei Verbgruppen
Heiban-Verben sind in ihrer Wörterbuchform flach. Sie haben keinen Akzentkern, und ihre Tonhöhe bleibt normalerweise bis in das nachfolgende Element hinein hoch. Ein typisches Beispiel ist 遊ぶ.
Kifuku-Verben sind akzentuiert. Ihre Wörterbuchform enthält einen Akzentkern, meist auf der
vorletzten Mora des Verbs: 食べる,
Flache Verben
Heiban-Verben beginnen flach, aber manche Endungen bringen einen eigenen neuen Akzent mit. Das Grundverb trägt keinen Akzentkern in die Konjugation hinein.
- Grundformあそぶ
- Höflichkeitsformあそびます
- Vergangenheit / te-Formあそんだ / あそんで
- Negativform Vergangenheitあそばなかった
- Wunschformあそびたい
- Konditionalformあそべば
- Negativformr Imperativあそぶな
Akzentuierte Verben
Kifuku-Verben haben bereits in der Wörterbuchform einen Akzentkern. Je nach Endung kann dieser ursprüngliche Akzentkern überschrieben, beibehalten oder nach links verschoben werden.
- Grundformたべる
- Höflichkeitsformたべます
- Negativformたべない
- Vergangenheit / te-Formたべた / たべて
- Wunschformたべたい
- Passivたべられる
- Konditionalformたべれば
Die Hauptregel: Endungen fügen Akzente hinzu, überschreiben sie oder verschieben sie
Die meisten Regeln der Verbkonjugation lassen sich in drei nützliche Muster einteilen:
- Die Endung fügt ihren eigenen Akzent hinzu. Das geschieht bei Endungen wie 〜ます, 〜たい, und 〜よう. Der Akzentkern erscheint innerhalb der angehängten Endung: あそびます, たべます.
- Die Endung ist akzentlos. Bei Heiban-Verben bleibt dadurch oft die ganze Form flach: 遊んで. Bei Kifuku-Verben verschiebt sich der Akzent häufig um eine Stelle nach links: たべて.
- Die Endung überschreibt den Basisakzent. Manche Endungen ersetzen den ursprünglichen Kifuku-Akzentkern durch einen neuen Akzentkern im Hilfselement: たべられる, たべさせる.
| Form | Flaches Beispiel | Kifuku-Beispiel | Was passiert |
|---|---|---|---|
| 〜ます | あそびます | たべます | Die Höflichkeitsendung trägt den Akzent. |
| 〜ない | あそばない | たべない | Kifuku-Verben fallen zwischen Stamm und ない. |
| 〜た / 〜て | あそんだ / あそんで | たべた / たべて | Kifuku-Verben verschieben den Akzentkern auf die drittletzte Mora. |
| 〜たい | あそびたい | たべたい | Die Endung たい trägt den Akzent. |
| 〜ば / 〜れば | あそべば | たべれば | Der Akzentkern landet auf der letzten Mora des Verbstamms. |
| Negativformr Imperativ | あそぶな | たべるな | Heiban-Verben fügen einen Akzentkern hinzu; Kifuku-Verben behalten den Basisabfall. |
Nützliche Faustregeln zum Erraten der Tonhöhengruppe
Das sind keine absoluten Gesetze, aber gute Abkürzungen, wenn du mal nicht weißt, ob ein Verb Heiban oder Kifuku ist:
- Zweimorige Verben auf 〜つ sind meist Kifuku ist:
待 つ立 つ勝 つ. - Die meisten Verben auf 〜ぶ sind Heiban: 遊ぶ, 飛ぶ, 運ぶ, 学ぶ. Häufige Ausnahmen, die tatsächlich Kifuku sind, sind unter anderem 選ぶ, 叫ぶ, und 喜ぶ.
- Viele dreimorige Verben mit einer Mora der い-Reihe in der Mitte sind Kifuku ist: 降りる, 過ぎる, 閉じる.
- Transitive und intransitive Verbpaare gehören meist zur selben Tonhöhengruppe: 並ぶ / 並べる, 返る / 返す, 降りる / 降ろす.
- Zusammengesetzte Verben neigen zu Kifuku ist:
分 かり合 う , 走りまわる.
Fortgeschrittene Ketten: 〜ている, Kontraktion und Höflichkeitsformen
Längere Verbketten verhalten sich wie Akzentphrasen, die aus mehreren Teilen aufgebaut sind. Das wichtigste Beispiel ist 〜ている. In sorgfältiger Aussprache kann man dies noch als Verb + て + いる, aber in gewöhnlicher Sprache wird es oft zu 〜てる. Das Tonhöhenmuster hängt zunächst davon ab, ob das ursprüngliche Verb Heiban oder Kifuku ist.
| Basistyp | Vollform | Kontrahierte Form | Tonhöhenverhalten |
|---|---|---|---|
| Heiban | している | してる | している, してる. |
| Kifuku | みている | みてる | みている, みてる. |
Höflichkeitsformen fügen eine weitere Ebene hinzu. Das Höflichkeitshilfsverb 〜ます hat sein eigenes Akzentverhalten, sodass Formen wie しています und みています als ganze Wörter nicht einfach „flach“ oder „akzentuiert“ sind. Es sind Ketten von Akzentphrasen.
| Basistyp | Form | Typisches Tonhöhenverhalten |
|---|---|---|
| Heiban | しています | しています |
| Heiban | していません | していません |
| Heiban | していました | していました |
| Kifuku | みています | みて・います |
| Kifuku | みていません | みて・いません |
| Kifuku | みていました | みて・いました |
Kontrahierte Höflichkeitsformen verhalten sich ähnlich: してます, してません, してました, und みて・ます, みて・ません, みて・ました.
In normaler Sprache ist der zweite Akzentkern in solchen Ketten oft deutlich abgeschwächt, besonders wenn die Phrase dort endet. Wenn aber nach der Höflichkeitsform noch etwas anschließt, etwa 〜でした oder 〜ので, wird der zweite Akzentkern oft deutlicher hörbar. Zum Beispiel: みて・ませんでした.
Deshalb lässt sich Tonhöhenakzent auf Satzebene nicht allein durch Nachschlagen der Wörterbuchform lösen. Der Parser muss entscheiden, wie das Grundverb, die 〜ている Kette, Kontraktion, Höflichkeit, Negation und nachfolgendes Material innerhalb einer Akzentphrase zusammenwirken.
Die Tonhöhe zusammengesetzter Nomen
Wenn zwei getrennte Nomen zu einem einzigen zusammengesetzten Nomen werden, (複合名詞), behalten sie nur selten ihre ursprünglichen isolierten Tonhöhenmuster. Stattdessen verschmelzen sie zu einer einzigen Akzentphrase. Damit das möglich ist, gibt eines der Wörter typischerweise seinen Akzent auf, sodass eine neue, einheitliche Tonhöhenkontur entsteht.
Der akusento-Parser löst dies, indem er Nominalsuffixe in fünf zentrale Kompositumsfälle einteilt.
1. 後部一型 (Letzterer-Teil-Startmuster)
In diesem Muster liegt der Akzentkern auf der ersten Mora des Suffixes (des hinteren Wortes). Egal wie lang das erste Wort ist: Die Tonhöhe bleibt hoch, bis sie die Grenze überschreitet und die erste Mora des zweiten Wortes erreicht.
Beispiel: Wenn ein Wort an das Suffix 〜確認 , anschließt, wird der Akzentkern auf か platziert. Zum Beispiel 安全 bildet dann folgendes Kompositum: 安全確認.
2. 前部末型 (Ersterer-Teil-Endmuster)
In diesem Muster liegt der Akzentkern auf der letzten Mora des ersten (vorderen) Wortes, also genau an der Grenze, bevor das Suffix beginnt.
Beispiel: Das Suffix 〜税 erzwingt, dass der Akzentkern auf der unmittelbar davorliegenden Mora liegt. Dadurch wird 消費 zu 消費税.
3. 後部保存型 (Letzterer-Teil-erhaltendes Muster)
Manchmal verändert das Suffix seine Tonhöhe nicht, wodurch das gesamte Kompositum das ursprüngliche Tonhöhenmuster des Suffixes selbst übernimmt. Das geschieht häufig, wenn das Suffix ein Nakadaka-Wort ist.
Beispiel: Das Wort 委員会 behält seinen Akzentkern auf dem zweiten い unabhängig davon, was davor angeschlossen wird. Das bedeutet aus 教育委員会 wird 教育委員会.
4. 平板型 (flaches Muster)
Das gesamte zusammengesetzte Nomen wird vollständig flach, wodurch alle Akzentkerne gelöscht werden, die in den ursprünglichen Wörtern vorhanden waren.
Beispiel: Das Anhängen von Suffixen wie 〜化 macht das neue Kompositum vollständig akzentlos. Zum Beispiel wird 機械化 zu 機械化.
5. 尾高型 (endhohes Muster)
Der Akzentkern wird ganz ans Ende des zusammengesetzten Wortes verschoben. Die Tonhöhe bleibt während des gesamten Kompositums hoch, fällt aber unmittelbar nach der letzten Mora ab und Partikel werden in tieferer Tonhöhe angehängt.
Beispiel: Das Zählsuffix 〜目 löst dieses Muster häufig aus. Zum Beispiel wird 一番目 gefolgt von der particle は ausgesprochen als 一番目は.
Kollisionsreparatur: der wandernde Akzentkern
Regeln der japanischen Phonologie sind normalerweise konsistent, kollidieren aber gelegentlich mit physischen Aussprachelimitationen. Das gilt besonders für das Ersterer-Teil-Endmuster (前部末型).
Zur Erinnerung: Beim Ersterer-Teil-Endmuster soll die Tonhöhe genau an der Grenze zwischen den beiden Wörtern abfallen. Ein Akzentkern kann jedoch nicht auf einer „Spezialmora“ liegen (特殊拍), etwa dem silbischen Nasal ん, der kleinen Pause っ, oder dem Langtonzeichen ー oder der zweiten Hälfte eines Diphthongs (wie dem い in けい).
Wenn die Wortgrenze direkt auf einen dieser „unerlaubten“ Taktschläge fällt, geht der Parser automatisch zurück und verschiebt den Akzentkern eine Mora nach vorn, um die Kollision zu beheben.
- Nasal-Kollision: 住民税. Das Suffix 〜税 erzwingt normalerweise unmittelbar davor einen Akzentkern. Aber 住民 endet auf ん, was eine unzulässige Position ist. Der Parser verschiebt den Akzentkern zurück auf み → 住民税.
- Langvokal-Kollision: 指定席. 〜席 erzeugt einen Akzentkern davor, aber 指定 endet auf い, das Teil des langen Vokals ist (てい). Der Akzentkern verschiebt sich zurück auf て → 指定席.
Wenn Wörter nicht verschmelzen (keine Kompositumbildung)
Wichtig ist: Nicht alle Nominalverbindungen verschmelzen zu einer einzigen Akzentphrase. Je nach ihrer grammatischen Beziehung widersetzen sich viele Kombinationen der Kompositumbildung. Statt zu verschmelzen, bleiben sie als zwei getrennte Akzentphrasen bestehen und bewahren ihre ursprünglichen separaten Tonhöhenmuster. Das geschieht typischerweise in folgenden Spezialfällen:
- Subjekt vs. Objekt (suru-Verben): Wenn das zweite Wort eine Handlung ist (ein suru-Verb) und das erste Wort das Subjekt ist, das diese Handlung ausführt, bilden sie kein Kompositum. Zum Beispiel 社長辞任 (Der Präsident tritt zurück). Wenn dagegen das erste Wort das Objekt ist, auf das sich die Handlung richtet, verschmelzen sie zu einer Phrase: 結果発表 (Bekanntgabe der Ergebnisse).
- Ausnahmen bei Handlungswörtern: Bestimmte Handlungswörter bilden selbst dann kein Kompositum, wenn sie sich auf ein Objekt beziehen. Suffixe wie 〜禁止 oder 〜中止 sind Beispiele dafür. Wenn du 駐車禁止 oder 原因不明, aussprichst, werden diese als zwei syntaktisch getrennte Einheiten behandelt.
Warum Standardwörterbücher bei Tonhöhenanalyse auf Satzebene scheitern
Wörter in einem Standardwörterbuch nachzuschlagen, ist für Karteikarten und schnelle Checks völlig in Ordnung, aber Japanisch wird nicht in isolierten Wörtern gesprochen. Tonhöhenakzent ist hochdynamisch und stark kontextabhängig. Wenn ein Wort konjugiert wird, an Partikel anschließt oder in Komposita und festen Wendungen verwendet wird, verschiebt sich der Akzentkern häufig oder verschwindet sogar vollständig durch Deakzentuierung. Manchmal kann ein Wort sogar mehrere akzeptierte Tonhöhenmuster haben. In den meisten Fällen sind diese dynamischen Veränderungen keine zufälligen Eigenheiten der Sprache. Sie entstehen aus den zugrunde liegenden phonologischen Mustern und grammatischen Regeln, die man lernen und recht effektiv anwenden kann.
Um wirklich zu verstehen, wie Tonhöhenakzent in einem vollständigen Satz funktioniert und wie der Satz klingen soll, ist eine kontextbewusste Analyse notwendig, die diese Regeln anwenden und transparent erklären kann. Betrachte das folgende Beispiel:「雨がやんだら出かけようと思っていたのに、結局そのまま本を読み続けてしまった。」Im Analysebeispiel unten kannst du auf jedes Wort klicken, um seine Tonhöhenakzent-Informationen und weitere wichtige Metadaten zu sehen. Achte darauf, wie die Tonhöhe fließt und sich in diesem komplexen Satz verschiebt, verglichen mit isolierten Vokabeln. Schau auch auf die ・ Markierungen, die dir zeigen, wo die Akzentphrasen beginnen und enden.
Häufig gestellte Fragen
Warum ist Tonhöhenakzent wichtig, wenn man mich aus dem Kontext versteht?
Kontext hilft oft dabei zu verstehen, was du meinst, macht Tonhöhenakzent aber nicht irrelevant. Falsche Tonhöhe kann sonst korrektes Japanisch unnatürlich, schwerer verständlich oder gelegentlich mehrdeutig wirken lassen. Das Ziel ist nicht Perfektion um ihrer selbst willen, sondern den Rhythmus deines Japanisch leichter für Muttersprachler verarbeitbar zu machen.
Was ist der Unterschied zwischen Tonhöhenakzent und Intonation?
Tonhöhenakzent ist die innere Hoch/Tief-Struktur einzelner Wörter, die auch Bedeutung unterscheiden kann. Intonation ist das Steigen und Fallen der Stimme über einen ganzen Satz hinweg, um Emotionen oder eine Frage auszudrücken.
Muss ich die Tonhöhe aller Konjugationen jedes Verbs und Adjektivs auswendig lernen?
Nein. Du musst nur wissen, ob die Wörterbuchform des Verbs oder Adjektivs flach (Heiban) oder akzentuiert (Kifuku) ist. Wenn du das weißt, folgt jede Konjugation – von der Vergangenheitsform bis zur Negativform – strengen und vorhersagbaren Regeln.
Wie finde ich den Tonhöhenakzent eines ganzen Satzes oder Ausdrucks?
Standardwörterbücher zeigen nur isolierte Wörter. Um zu sehen, wie sich die Tonhöhe im Satz verändert, wenn Partikeln und Konjugationen hinzukommen, brauchst du einen Parser wie akusento, der Satzkontext analysiert.
Behandelt akusento auch regionale Dialekte?
Nein, akusento konzentriert sich ausschließlich auf Standard-Tokyo-Japanisch (標準語). Das ist die Standardaussprache, die in landesweiten Rundfunksendungen, Nachrichten und den meisten Medien wie Anime oder J-Dramen verwendet wird. Regionale Dialekte wie Kansai-ben verwenden völlig andere Tonhöhenakzentsysteme.